دادگاه عالی کلمبیا با ابزارهای ناقص شناسایی هوش مصنوعی، حکم خود را زیر سوال برد

دادگاه عالی کلمبیا با استناد به نتایج ابزار شناسایی متون هوش مصنوعی، یک درخواست فرجامخواهی را رد کرد. وکلای معترض با استفاده از همان ابزار، حکم دادگاه را نیز بررسی کردند و مشخص شد که خود این حکم نیز با احتمال بالا توسط هوش مصنوعی تولید شده است. این ماجرا ضعف فنی و خطرات تکیه بر این نرمافزارهای تشخیص را در محیطهای حساسی مانند نظام قضایی آشکار کرد.
نکات کلیدی
– دادگاه عالی کلمبیا درخواست فرجامی را به دلیل تشخیص ۹۳٪ محتوای ماشینی توسط ابزار Winston AI رد کرد.
– وکلای معترض متن حکم دادگاه را در همان ابزار Winston AI قرار دادند و نتیجه نشان داد ۹۳٪ از خود حکم نیز توسط هوش مصنوعی تولید شده است.
– آزمایشهای بیشتر با ابزارهایی مانند GPTZero نتایج متناقض و کاملاً غیرقابل اعتمادی را نشان داد.
– مطالعات آکادمیک نشان میدهد این ابزارها اغلب نوشتههای رسمی، متون آکادمیک و نوشتههای غیرانگلیسیزبانان را به اشتباه هوش مصنوعی تشخیص میدهند.
– بسیاری از دانشگاههای معتبر جهان به دلیل نرخ بالای خطا، استفاده از این تشخیصدهندهها را متوقف کردهاند.
– رهنمودهای قضایی کلمبیا استفاده از هوش مصنوعی برای ارزیابی ادله یا تفسیر قانون را صراحتاً ممنوع کرده است.
– این پرونده یکی از اولین رویاروییهای قضایی با چالش سوءاستفاده از هوش مصنوعی در اسناد حقوقی در منطقه آمریکای لاتین محسوب میشود.
یک حکم جنجالی و کشف تناقض
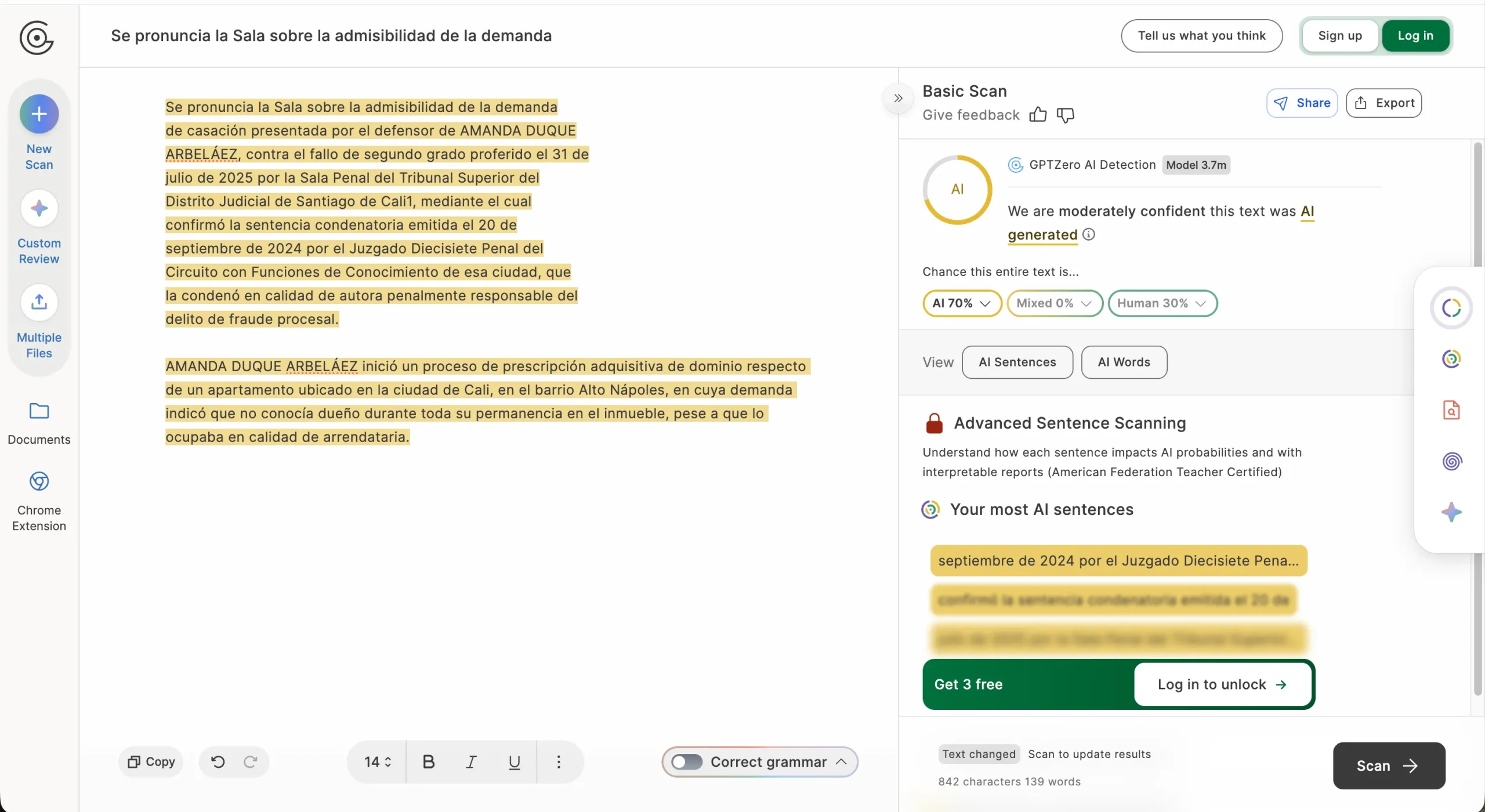
دادگاه عالی کلمبیا با صدور حکمی در پرونده AP760/2026، یک درخواست فرجامخواهی را به دلیل «مشکوک بودن به تولید توسط هوش مصنوعی» غیرقابل استماع اعلام کرد. این دادگاه برای رسیدن به این نتیجه، متن درخواست وکیل را به ابزار شناسایی هوش مصنوعی Winston AI سپرده بود. گزارش این ابزار نشان میداد که تنها ۷٪ از محتوای سند، اثر انسانی دارد و ۹۳٪ باقیمانده با کمک هوش مصنوعی تولید شده است.
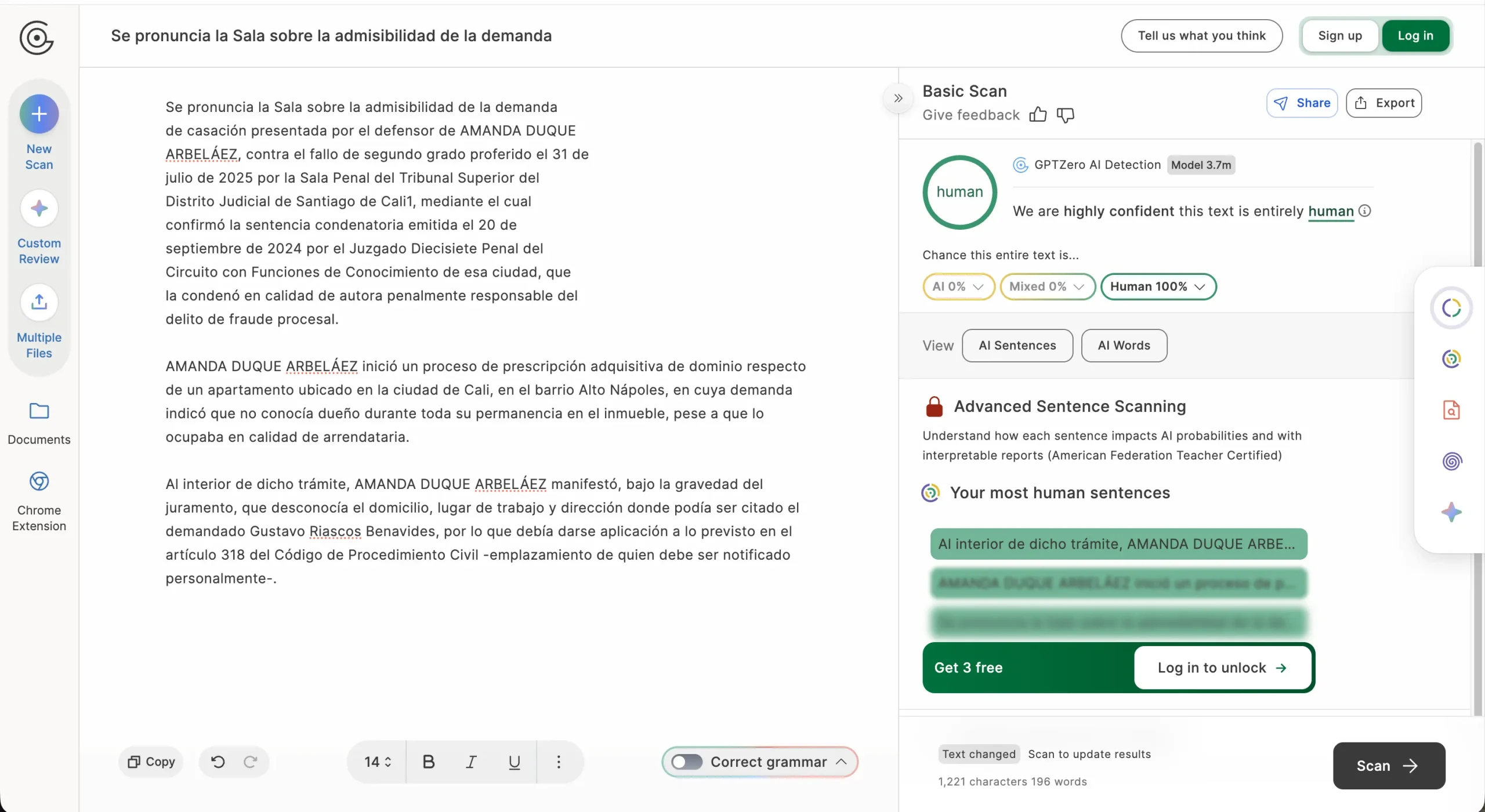
پس از انتشار این حکم، امانوئل آلسو ولاسکز، یکی از وکلای کلمبیایی، اقدام به آزمایشی جالب کرد. او متن کامل حکم دادگاه عالی را وارد همان نرمافزار Winston AI کرد. نتیجه شوکهکننده بود: این ابزار اعلام کرد که ۹۳٪ از متن حکم دادگاه نیز توسط هوش مصنوعی تولید شده است. ولاسکز در شبکه اکس (توییتر سابق) تاکید کرد که این تناقض، شکنندگی روششناختی استفاده از چنین تشخیصدهندههایی را به عنوان پشتوانه استدلال قضایی به وضوح نشان میدهد.
ابزارهای تشخیص؛ بازی با اعداد غیرقابل اعتماد
پس از viral شدن این موضوع در محافل حقوقی، وکلای دیگر نیز دست به آزمایش زدند. نتایج به وضوح نشان داد که این ابزارها نه تنها قابل اعتماد نیستند، بلکه نتایج متناقضی ارائه میدهند. به عنوان مثال، هنگامی که تنها بخش ابتدایی حکم دادگاه در ابزار GPTZero قرار داده شد، نتیجه «۱۰۰٪ هوش مصنوعی» بود. اما با افزودن بخشهای بیشتری مانند زمینههای واقعی پرونده، نتیجه به طور کامل معکوس شد و «۱۰۰٪ انسان» اعلام گردید.
آزمایشهای دیگر عمق فاجعه را نشان داد. یک وکیل، متن دادخواستی از سال ۲۰۱۹ را که سالها قبل از ظهور مدلهای زبانی بزرگ نوشته شده بود، مورد آزمایش قرار داد و نتیجه ۹۵٪ تولید هوش مصنوعی بود. دیگری پایاننامه کارشناسی خود در سال ۲۰۲۰ را آزمایش کرد و نتیجه ۱۰۰٪ هوش مصنوعی گرفت. این نتایج اثبات میکند که این ابزارها اساساً برای تشخیص متون رسمی، حقوقی و آکادمیک که از الگوهای زبانی ثابت و قابل پیشبینیتری پیروی میکنند، طراحی نشدهاند.
چرا تشخیصدهندهها شکست میخورند؟
دلایل فنی این شکست به خوبی مستند شده است. ابزارهای شناسایی هوش مصنوعی الگوهای آماری مانند طول جملات، پیشبینیپذیری واژگان و ویژگیای به نام «burstiness» یا تغییرات ریتم طبیعی در نوشتار انسان را اندازهگیری میکنند. مشکل اصلی اینجاست که نثر رسمی حقوقی، نوشتار آکادمیک و متونی که توسط افرادی که به زبان دوم مینویسند تولید میشوند، بسیاری از همین امضاهای آماری را دارند.
مطالعات متعدد این ضعف را تایید کردهاند. یک پژوهش در سال ۲۰۲۳ در مجله Patterns نشان داد که بیش از ۶۱٪ از مقالات آزمون تافل (TOEFL) که توسط غیرانگلیسیزبانان نوشته شده بود، به اشتباه به عنوان تولید هوش مصنوعی پرچمگذاری شد. یک بررسی سیستماتیک در همان سال توسط «وبر-وولف» نتیجه گرفت که هیچ ابزار در دسترسی دقیق یا قابل اعتماد نیست. حتی شرکت OpenAI نیز مجبور شد ابزار تشخیصی خود را به دلیل نادرستیهای مداوم از دسترس خارج کند.
تاثیرات فرهنگی و قضایی فراتر از متن
تکیه بر این ابزارهای ناقص، پیامدهای فرهنگی عجیبی نیز به همراه داشته است. در محافل نویسندگی و روزنامهنگاری، برخی افراد شروع به حذف علائم نگارشی خاصی مانند «ام دش» از نوشتههای خود کردهاند. نه به دلیل رعایت سبک نگارشی، بلکه چون مدلهای زبانی هوش مصنوعی از این علائم زیاد استفاده میکنند و ابزارهای تشخیص (و حتی انسانها) به آن حساس شدهاند. این یعنی نویسندگان در حال ویرایش طبیعیترین عناصر نوشتار خود از ترس سوءظن الگوریتمی هستند.
در عرصه قضایی، پرونده کلمبیا به همراه پرونده دیگری با شماره AC739-2026 (که در آن یک وکیل به دلیل استناد به ۱۰ سابقه قضایی ساختگی تولیدشده توسط هوش مصنوعی جریمه شد) از اولین تصمیمات قضایی منطقه در مواجهه مستقیم با سوءاستفاده از هوش مصنوعی تولیدی در اسناد حقوقی محسوب میشود. نکته قابل تامل این است که قوه قضائیه کلمبیا در دسامبر ۲۰۲۴ رهنمودهای رسمی (موافقتنامه PCSJA24-12243) را تصویب کرده که صراحتاً استفاده از هوش مصنوعی برای ارزیابی ادله، تفسیر قانون یا اتخاذ تصمیمات قضایی را ممنوع میکند و بر مسئولیت کامل قضات انسانی تاکید دارد.
این رهنمودها میتواند مبنای اعتراض به حکم اخیر دادگاه عالی باشد.
درسهایی برای آینده
واکنش دادگاه عالی کلمبیا به انتقادات وارده درباره انتخاب ابزارهای تشخیص، تاکنون انتشار بیانیهای اضافی نبوده است. این ماجرا یک هشدار جدی برای تمامی نهادهای قضایی، آموزشی و حرفهای در سراسر جهان است. استفاده از فناوریهای ناپخته و اثباتنشده در تصمیمگیریهایی که سرنوشت انسانها را تغییر میدهد، میتواند به بیاعتمادی گسترده و نقض حقوق اساسی افراد منجر شود.
همانطور که داريو كابررا مونتئالگر، وکیل کلمبیایی اشاره کرد، تناقض ذاتی در این رویکرد وجود دارد: «دادگاه از هوش مصنوعی استفاده میکند تا تشخیص دهد آیا هوش مصنوعی استفاده شده است؟ اگر قرار باشد درخواستی رد شود، باید به این دلیل باشد که ما به عنوان انسان آن را تشخیص دادهایم.» راه حل، نه در حذف فناوری، که در پذیرش محدودیتهای آن و حفظ نقش محوری قضاوت انسانی است.