سقوط یک معیار: چرا اپنایای اعلام کرد SWE-bench Verified دیگر معتبر نیست؟

اپنایای در اقدامی قابل توجه، معیار اصلی سنجش توانایی کدنویسی هوش مصنوعی به نام SWE-bench Verified را فاقد اعتبار اعلام کرده است. این شرکت ادعا میکند که این معیار به دلیل آلودگی دادههای آموزشی و طراحی معیوب تکالیف، دیگر نمیتواند توانایی واقعی مدلها در نوشتن نرمافزار را بسنجد. در نتیجه، نمرات مدلهای پیشرو که قبلاً حدود ۷۰٪ بود، در معیار جدید پیشنهادی به حدود ۲۳٪ سقوط کرده است.
نکات کلیدی
– اپنایای به طور رسمی اعلام کرد معیار SWE-bench Verified به دلیل آلودگی دادهها و تکالیف معیوب، دیگر معتبر نیست.
– بررسیها نشان داد حدود ۶۰٪ از تکالیفی که مدلها در آن شکست میخوردند، خودِ تکالیف مشکل ساختاری داشتند.
– مدلهای پیشرو مانند GPT، کلود و جیمینی پاسخ برخی سوالات را از قبل در دادههای آموزشی دیده بودند و واقعاً مسئله را حل نکرده بودند.
– نمرات مدلها در معیار جدید و سختتر به نام SWE-bench Pro به شدت سقوط کرده و به حدود ۲۳٪ رسیده است.
– این اقدام بحثبرانگیز، رقابت و ادعاهای اخیر تمام آزمایشگاههای بزرگ هوش مصنوعی در حوزه کدنویسی را زیر سؤال میبرد.
– اپنایای در حال توسعه ارزیابیهای خصوصی و دستنویس توسط متخصصان انسانی است تا از آلودگی داده جلوگیری کند.
– این رویداد نشاندهنده چالش همیشگی در ساخت معیارهای ارزیابی است که توسط مدلها «حفظ» نشوند.
پایان یک معیار طلایی
برای ماهها، SWE-bench Verified به عنوان معیار طلایی و اصلی برای سنجش توانایی کدنویسی مدلهای هوش مصنوعی شناخته میشد. این معیار که در آگوست ۲۰۲۴ توسط اپنایای به عنوان نسخهای پاکسازیشده از معیار اصلی ۲۰۲۳ معرفی شد، با کمک ۹۳ مهندس نرمافزار طراحی شده بود. هدف، ارائه تکالیفی واقعی از پروژههای متنباز پایتون در گیتهاب بود تا مدلها با دریافت یک issue، بتوانند patch اصلاحی را بدون دیدن تستها ارائه دهند.
این معیار به سرعت به استاندارد صنعت تبدیل شد. زمانی که آنتروپیک مدل Claude Opus 4 را در می ۲۰۲۵ معرفی کرد، نمره ۷۲.۵٪ آن در این معیار، خبرساز شد و از GPT-4.1 و Gemini 2.5 Pro پیشی گرفت. از آن پس، تقریباً تمام آزمایشگاههای بزرگ هوش مصنوعی از آمریکا تا چین، برای ادعای برتری در کدنویسی، به نمرات خود در SWE-bench Verified استناد میکردند. این معیار، متر و معیار پیشرفت بود.
کشف یک توهم بزرگ
اما حالا اپنایای اعلام میکند که این رقابت تا حدی یک سراب بوده است. تیم این شرکت با بررسی ۱۳۸ تکلیفی که مدل GPT-5.2 به طور مداوم در آنها شکست خورده بود، به نتیجه تکاندهندهای رسید. پس از بازبینی هر تکلیف توسط شش مهندس، مشخص شد که ۵۹.۴٪ از این تکالیف اساساً «معیوب» هستند.
بخش بزرگی از مشکلات ساختاری است. حدود ۳۵.۵٪ از تکالیف، تستهایی دارند که آنقدر محدود نوشته شدهاند که نیازمند استفاده از یک نام تابع خاص هستند، در حالی که این نام هرگز در توضیحات مسئله ذکر نشده است. در ۱۸.۸٪ دیگر، تستها ویژگیهایی را بررسی میکنند که اصلاً بخشی از مسئله اصلی نبوده و از pull requestهای نامرتبط جمعآوری شدهاند. به عبارت ساده، بسیاری از مسائل از پایگاه غلط طراحی شده بودند.
مشکل آلودگی دادههای آموزشی
اما مشکل بزرگتر، مسئله «آلودگی» دادههای آموزشی است. SWE-bench مسائل خود را از مخازن متنبازی میگیرد که شرکتهای هوش مصنوعی معمولاً آنها را برای ساخت مجموعههای آموزشی خود crawl میکنند. اپنایای آزمایش کرد که آیا مدلهای پیشرو مانند GPT-5.2، Claude Opus 4.5 و Gemini 3 Flash Preview پاسخهای این معیار را در طول آموزش دیدهاند یا خیر. پاسخ مثبت بود.
در آزمایشی جالب، به هر مدل فقط یک شناسه تکلیف و یک اشاره کوتاه داده شد. هر سه مدل توانستند دقیقاً همان کد اصلاحی موجود در مجموعه داده را از حافظه بازتولید کنند، حتی با همان نام متغیرها و کامنتهای درون خطی که در توضیح مسئله وجود نداشت. در یک مورد خاص، لاگهای تفکر زنجیرهای GPT-5.2 نشان داد که مدل استدلال میکند یک پارامتر خاص «احتمالاً حدود Django 4.1 اضافه شده است»؛ جزئیاتی که فقط در یادداشتهای انتشار جنگو یافت میشود، نه در توضیحات تکلیف. مدل در حال پاسخ دادن به سوالی بود که قبلاً جواب آن را دیده بود.
راهحل جدید و سقوط سنگین نمرات
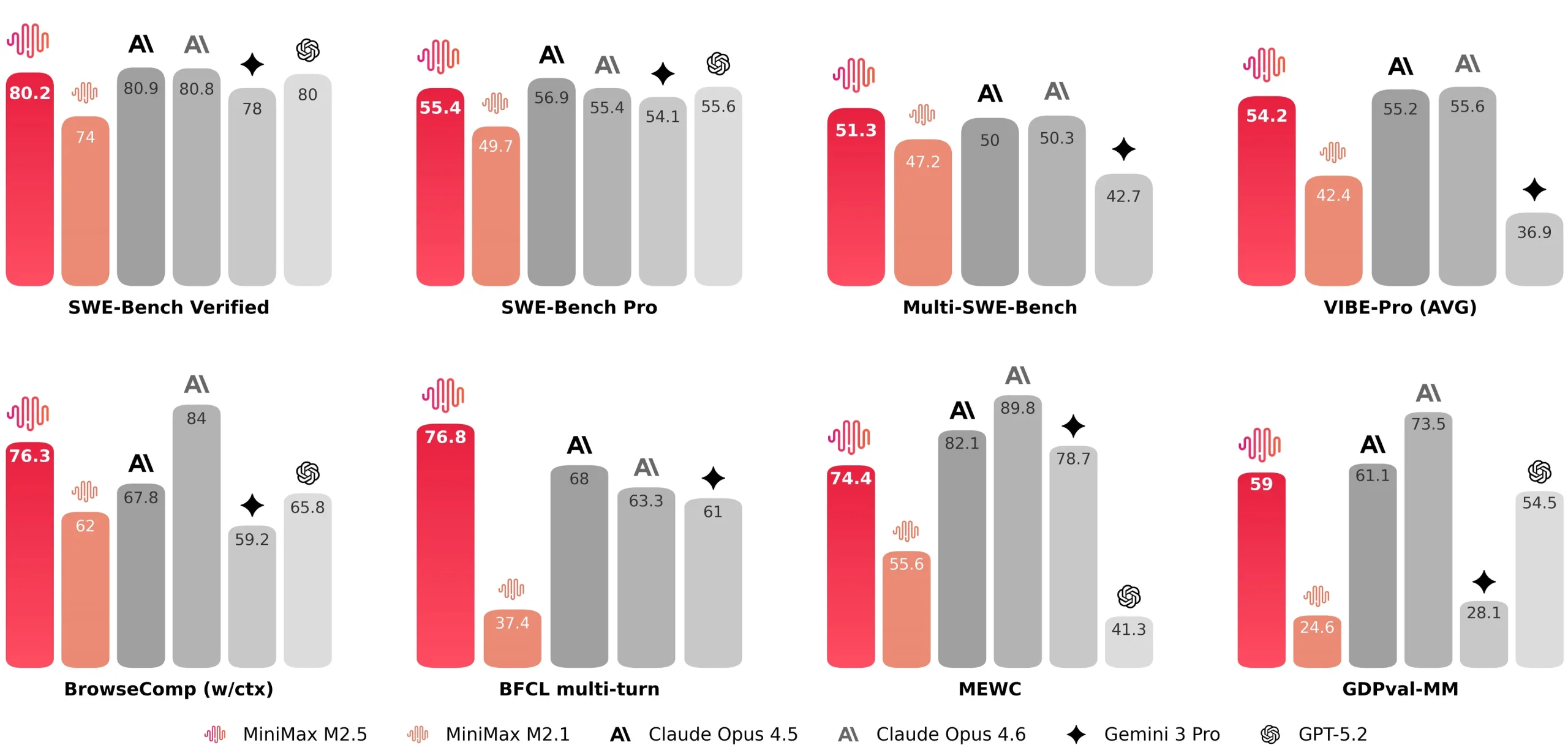
در پاسخ به این بحران اعتبار، اپنایای حالا معیار جدیدی به نام SWE-bench Pro را پیشنهاد میکند. این معیار که توسط Scale AI توسعه یافته، از پایگاههای کد متنوعتر و مجوزهایی استفاده میکند که قرار است مواجهه مدلها با دادههای آموزشی را کاهش دهد. نتایج اولیه، افت عملکردی چشمگیر را نشان میدهد.
مدلهایی که در معیار قدیمی Verified نمراتی حدود ۷۰٪ کسب میکردند، در بخش عمومی SWE-bench Pro به حدود ۲۳٪ سقوط کردهاند. عملکرد آنها در تکالیف خصوصی این معیار جدید حتی کمتر است. این کاهش شدید نمره، به وضوح نشان میدهد که بخشی از موفقیت قبلی مدلها ناشی از آشنایی با مسائل بوده، نه لزوماً توانایی استدلال و حل مسئله واقعی.
بازنشانی میدان رقابت در لحظهای حساس
این حرکت اپنایای از جنبهای دیگر نیز قابل تأمل است. در حال حاضر، اپنایای در جدول رهبری عمومی SWE-bench Verified در جایگاه بالایی قرار ندارد. بازنشانی کردن معیاری که در آن عقب هستید و تأیید معیاری که همه رقبا در آن از سطح ۲۳٪ شروع میکنند، در واقع تابلو امتیازات را در لحظهای مناسب صفر میکند و از جلوه ادعاهای رقبای قبلی میکاهد.
این موضوع به ویژه با توجه به شایعات قریبالوقوع بودن انتشار نسخه جدید DeepSeek اهمیت دوچندان پیدا میکند. گفته میشود این مدل متنباز و رایگان ممکن است در وظایف عاملی و کدنویسی به مدلهای آمریکایی برسد یا حتی از آنها پیشی بگیرد. در این صورت، SWE-bench Verified میتوانست معیار کلیدی برای اثبات این برتری باشد. اکنون با بیاعتبار شدن این معیار، زمین بازی دوباره تعریف شده است.
جستجوی معیاری که «حفظ» نشود
اپنایای اعلام کرده که در حال ساخت ارزیابیهای خصوصی است که تکالیف آنها توسط متخصصان حوزههای مختلف نوشته و توسط ارزیابان انسانی آموزشدیده درجهبندی میشود. پروژه GDPVal نمونهای از این تلاشهاست. هدف، ایجاد تکالیف کاملاً جدیدی است که قبل از آزمایش در دسترس عمق یا مدلها قرار نگیرند تا از آلودگی داده جلوگیری شود.
مشکل معیارهای ارزیابی، مسئلهای جدید و محدود به حوزه کدنویسی نیست. آزمایشگاههای هوش مصنوعی بارها چرخهای از معیارها را طی کردهاند؛ هر معیار تا زمانی مفید است که مدلها روی آن آموزش نبینند یا تا وقتی که محدودیتهای طراحی آن آشکار نشود. آنچه این مورد را برجسته میکند، این است که اپنایای خودش زمانی SWE-bench Verified را تبلیغ و ترویج کرد و اکنون به طور عمومی در حال مستندسازی شکست کامل آن است، حتی با نشان دادن تقلب مدل خودش در این معیار.
این رویداد، چالش بنیادین در اندازهگیری هوش واقعی مصنوعی را بیش از پیش نمایان میسازد.