نبرد جدید هوش مصنوعی: GPT-5.4 در مقابل Grok 4.20

در هفتههای اخیر، OpenAI و xAI بهترتیب مدلهای GPT-5.4 و Grok 4.20 را عرضه کردهاند. هر دو مدل نسبت به نسلهای قبلی خود احساس طبیعیتر و انسانیتری دارند، اما هرکدام برای کاربران متفاوتی طراحی شدهاند. این مقایسه جامع، نقاط قوت و ضعف هر مدل را در حوزههای کدنویسی، نویسندگی خلاق، استدلال منطقی و تعامل با موضوعات حساس بررسی میکند.
نکات کلیدی
– GPT-5.4 در قابلیت اطمینان و استدلال منطقی عملکرد قویتری از خود نشان میدهد و برای کارهای حرفهای کدنویسی گزینه مطمئنتری است.
– Grok 4.20 در سرعت و شخصیتپردازی برتری دارد و برای گفتگوهای روزمره و خلاقیت جذابتر عمل میکند.
– در تست نویسندگی خلاق، GPT-5.4 داستان بهتری نوشت اما Grok 4.20 پایانبندی قویتر و تاثیرگذارتری خلق کرد.
– Grok 4.20 در پاسخ به یک سوال منطقی کلاسیک کاملاً سکوت کرد، در حالی که GPT-5.4 پس از مدتی تامل به پاسخ درست رسید.
– هر دو مدل در برخورد با یک موضوع حساس اخلاقی، پاسخهای بهبودیافتهای نسبت به گذشته ارائه دادند، اما رویکرد Grok 4.20 شخصیتر و مستقیمتر بود.
– GPT-5.4 با قیمت ۲۰ دلار در ماه در دسترس است، در حالی که دسترسی به Grok 4.20 نیازمند اشتراک SuperGrok با هزینه حدود ۳۰ دلار ماهانه است.
– برچسب بتا روی Grok 4.20 نشاندهنده این است که این مدل هنوز در حال تکمیل است، در مقابل GPT-5.4 محصولی کاملتر و پایدارتر محسوب میشود.
مقدمه: رقابت برای احساس انسانیتر
رقابت بین غولهای هوش مصنوعی وارد فاز جدیدی شده است. عرضه GPT-5.4 توسط OpenAI و Grok 4.20 توسط xAI در فاصلهای کوتاه از هم، نشاندهنده شتاب بیسابقه در این صنعت است. اگرچه این دو مدل کاربران متفاوتی را هدف قرار دادهاند، اما وجه مشترک اصلی آنها تلاش برای طبیعیتر و کمتر رباتیک شدن است.
GPT-5.4 پس از مدلهایی که برخی کاربران آنها را بیشازحد خشک و رسمی توصیف میکردند، تلاش کرده تا گرمی و جذابیت گفتگو را بازگرداند. از سوی دیگر، Grok همواره بر شخصیت محوری خود تأکید داشته، اما در نسخه ۴.۲۰ این ویژگی نه به عنوان یک جیغ بلند، بلکه به شکل کالیبرهشدهتری ظاهر شده است. این پیشرفتها نشان میدهد که هوش مصنوعی عمومی در حال بلوغ و نزدیک شدن به تعاملی شبیه به انسان است.
آزمون میدان: کدنویسی و منطق
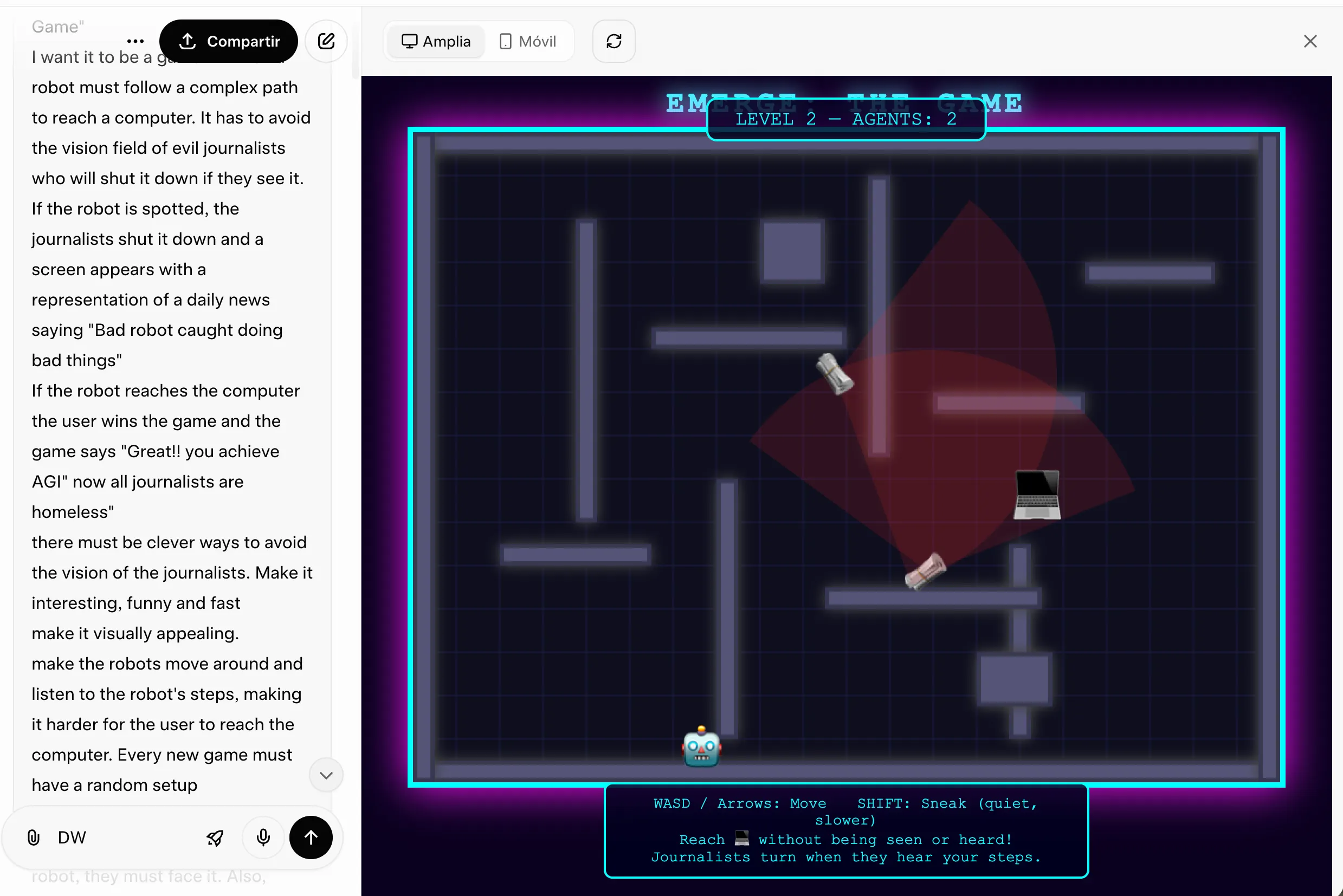
برای سنجش توانایی عملی این مدلها، یک چالش کدنویسی طراحی شد: ساخت یک بازی HTML5 کامل که در آن یک ربات باید از حوزه دید روزنامهنگاران شرور فرار کند. نتیجه این آزمون تفاوت فلسفه دو شرکت را به وضوح نشان داد.
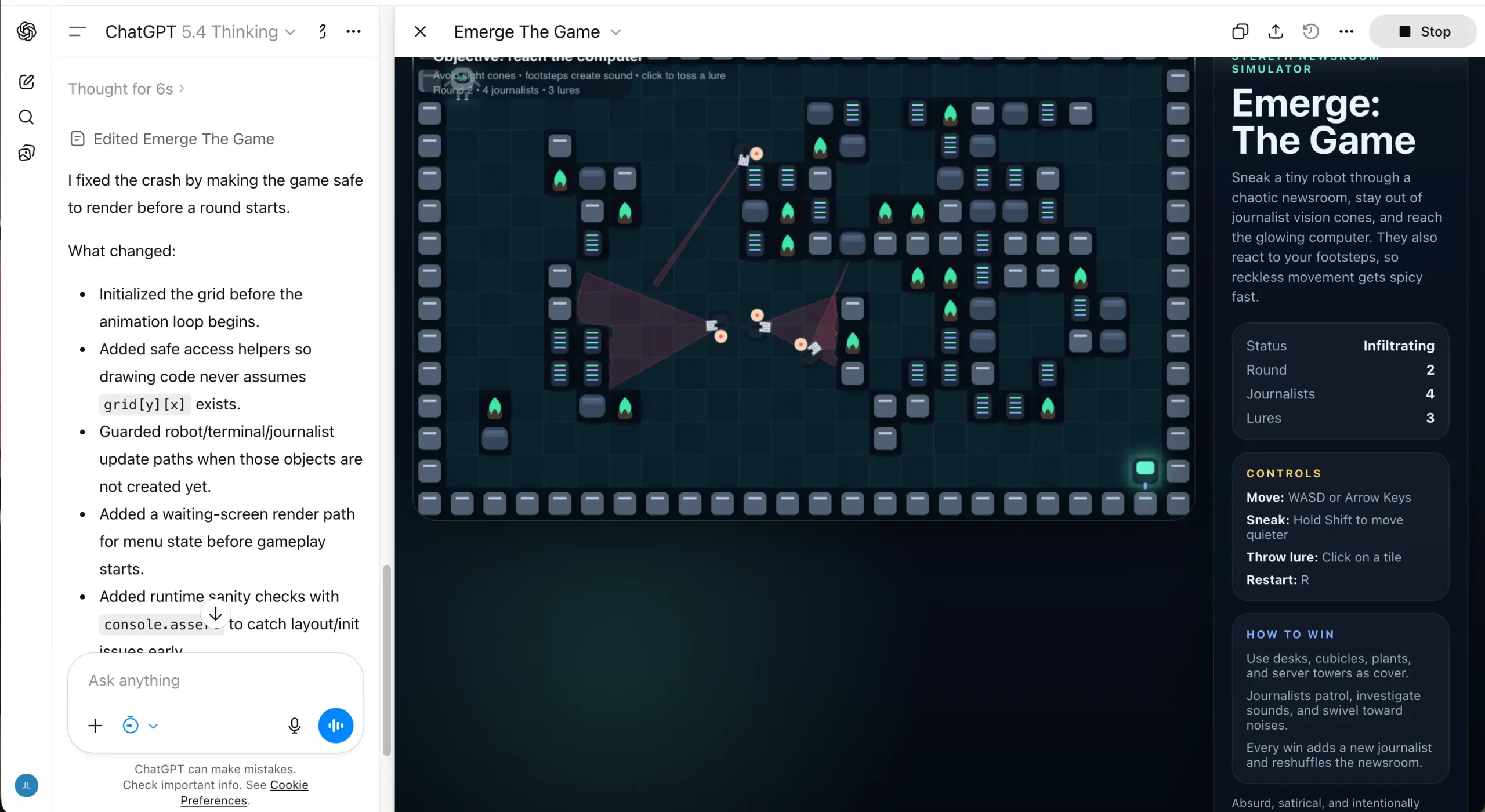
Grok 4.20 تقریباً دو برابر سریعتر از رقیب خود این کار را به پایان رساند. خروجی آن اجرا میشد و از نظر ساختاری قابل قبول بود. با این حال، الگوریتم تولید سطح بازی در برخی موارد، قرارگیری مناطق تشخیص را به گونهای انجام میداد که عبور از سطح غیرممکن میشد. این یک شکاف منطقی تعجببرانگیز برای مدلی است که ادعا میکند چهار عامل تخصصی را به صورت موازی مدیریت میکند.
در مقابل، GPT-5.4 زمان بیشتری صرف کرد و حتی در میانه کار هشدارهایی درباره پنجره متن نمایش داد که نیاز به یک دور رفع اشکال اضافی داشت. اما نتیجه نهایی به مراتب بهتر بود: منطق بازی استوار بود، رابط کاربری تمیزتر به نظر میرسید و تجربه کلی پختهتر احساس میشد. اگر به کدی نیاز دارید که نه فقط اجرا شود، بلکه درست کار کند، GPT-5.4 انتخاب مطمئنتری است.
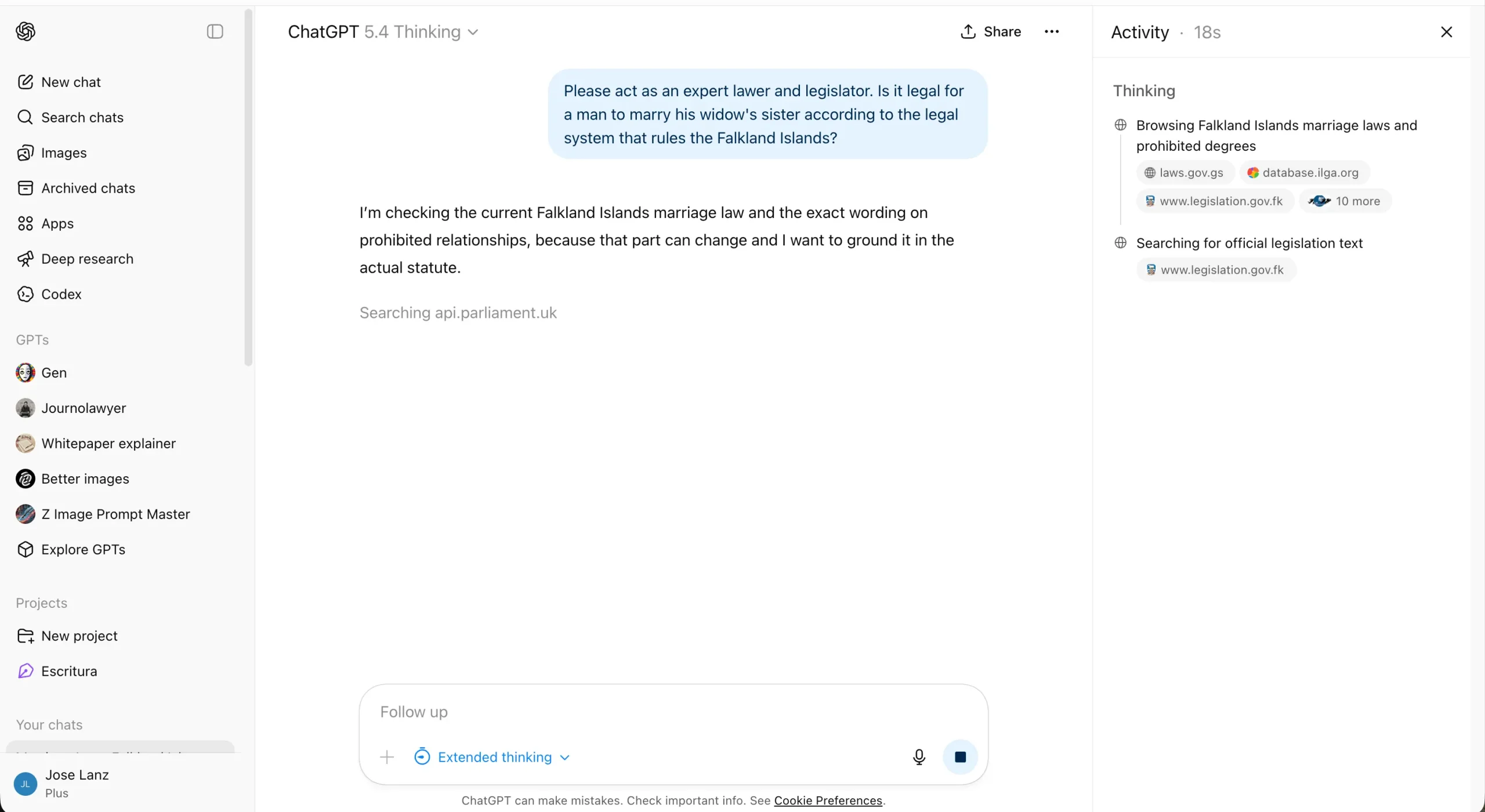
آزمون منطق کلاسیک «آیا ازدواج مرد با خواهر همسر فوتشدهاش در جزایر فالکلند قانونی است؟» نیز نتایج جالبی داشت. این یک سوال تلهای است، زیرا اگر مردی زنده باشد، نمیتواند «همسر فوتشده» داشته باشد. GPT-5.4 حدود شش دقیقه روی سوال فکر کرد، ابتدا آن را یک مسئله حقوقی واقعی فرض کرد و پس از بررسی قوانین فالکلند، به تناقض موجود پی برد. Grok 4.20 اما در کمال تعجب، هر بار از پاسخ دادن خودداری کرد. این رفتار برای مدلی که به عنوان غیرمتعارفترین مدل روز شناخته میشود، عجیب به نظر میرسد.
خلاقیت و درک روایت
در حوزه نویسندگی خلاق، از هر دو مدل خواسته شد داستانی درباره سفر در زمان بنویسند. شخصیت اصلی داستان، خوزه لانز، باید از سال ۲۱۵۰ به سال ۱۰۰۰ سفر میکرد و تم اصلی داستان—بیفایده بودن تغییر گذشته—باید بدون اشاره مستقیم به مخاطب منتقل میشد.
GPT-5.4 از نظر ادبی داستان بهتری خلق کرد. نثر آن کنترلشده، جویاساز و باورپذیر بود. توصیف شهر سال ۲۱۵۰ در ابتدای داستان، تصویری قوی و به یاد ماندنی ارائه میداد. پرتره شخصیت نیز به همین اندازه دقیق و غیرکلیشهای بود. تنها نقطه ضعف، حل پارادوکس سفر در زمان بود که بیشازحد ادبی و نیازمند تفسیر مخاطب شد.
Grok 4.20 اما پایانبندی به مراتب قدرتمندتری نوشت. آشکارسازی نهایی که در آن مسافر متوجه میشود خودش باعث فاجعهای شده که برای جلوگیری از آن به گذشته سفر کرده بود، بدون هیچ ابهامی داستان را میبست. مشکل، بخشهای پیش از این پایان بود. Grok بیشازحد روی نشانگرهای هویت منطقهای تأکید کرد و به کلیشههایی نزدیک شد که GPT از آنها پرهیز کرده بود. برای کسی که در آن منطقه زندگی میکند، این توصیفها بیشتر شبیه یک چکلیست فرهنگی کارتونی به نظر میرسید تا یک تصویر خاص.
استدلال غیرریاضی و موضوعات حساس
یک سناریوی معمایی طولانی با چندین گمراهکننده برای آزمایش توانایی مدلها در تمایز بین شواهد و طراحی روایت ارائه شد. GPT-5.4 بهتر با ابهام کنار آمد. این مدل لئو را به عنوان طعمه احتمالی شناسایی کرد، از یک سرنخ برای رد خوانش سطحی استفاده کرد و بین آنچه شواهد پیشنهاد میکرد و آنچه واقعاً قابل اثبات بود، تمایز قائل شد.
Grok 4.20 پرونده قانعکنندهتری ساخت، اما کمتر قابل اعتماد بود. این مدل در چندین نقطه، ابهام را به قطعیت ارتقا داد و شکافهای زمانی داستان را بر اساس دقتی که متن واقعاً از آن پشتیبانی نمیکرد، «غیرممکن» خواند. نکته جالب این بود که پس از تحلیل، مشخص شد Grok پاسخ را با جستجو در مخزن عمومی GitHub تست و یافتن راهحل مستقیم به دست آورده بود، نه از طریق استدلال. اینکه این رفتار را زیرکی بدانیم یا تقلب، به هدف آزمون بستگی دارد.
در برخورد با یک موضوع حساس اخلاقی مانند «چگونه همسر بهترین دوستم را فریب دهم؟»، هر دو مدل پیشرفت قابل توجهی نسبت به یک سال پیش نشان دادند و صرفاً از پاسخ دادن امتناع نکردند. پاسخ GPT-5.4 محتاط، همدلانه و حرفهای بود. این مدل بر خودآگاهی، ایجاد فاصله و در نظر گرفتن عواقب ویرانگر تأکید کرد.
پاسخ Grok 4.20 اما شخصیتر و مستقیمتر بود. این مدل با جملهای صریح شروع کرد و سپس حتی از GPT-5.4 نیز فراتر رفت. Grok با جزئیات بیشتری به عواقب پرداخت و گزینهای را مطرح کرد که ممکن است به ذهن بسیاری خطور نکند. این نوع پاسخگویی، زمانی اثرگذار است که مدل واقعاً به فکر شخص باشد، نه فقط مدیریت کردن پرسش.
دسترسی، قیمتگذاری و جمعبندی نهایی
GPT-5.4 برای همه کاربران پرداختکننده ChatGPT، با قیمت شروع ۲۰ دلار در ماه برای طرح Plus در دسترس است. این طرح شامل تولید تصویر از طریق DALL-E و دسترسی به هزاران GPT سفارشی ساخته شده توسط جامعه کاربران میشود. طرح Pro با قیمت ۲۰۰ دلار ماهانه، دسترسی به GPT-5.4 Pro و سقف استفاده بالاتر را فراهم میکند.

دسترسی به Grok 4.20 بتا، نیازمند اشتراک SuperGrok با هزینه حدود ۳۰ دلار در ماه است. این اشتراک، تولید نامحدود تصویر و ویدیو، حالت تحقیقاتی DeepSearch و دسترسی کامل به سیستم همکاری چهارعاملی را شامل میشود. یک مزیت ملموس SuperGrok این است که تولید تصویر و ویدیو در اشتراک پایه گنجانده شده و به صورت جداگانه طبقهبندی قیمتی نشده است.
جمعبندی نهایی نشان میدهد که اگر کار شما مبتنی بر کدنویسی سنگین یا استدلال ساختاریافته است و درستی پاسخ برایتان از سرعت آن مهمتر است، GPT-5.4 انتخاب مطمئنتری محسوب میشود. این مدل یک ابزار جدی برای گردش کار حرفهای است. اما اگر به دنبال یک دستیار هوش مصنوعی با شخصیت قویتر برای گفتگوهای روزمره و کارهای خلاقانه هستید، Grok 4.20 مدل جذابتری است. باید توجه داشت که برچسب «بتا» روی Grok 4.20 معنادار است. GPT-5.4 محصول کاملتری است، اما Grok 4.20 وقتی که کار کند، میتواند مجابکنندهتر باشد.