نقطه ضعف مرگبار هوش مصنوعی: دادههای ناقص انقلاب را تضعیف میکند — راه حل اینجاست
بیایید تظاهر را کنار بگذاریم: انقلاب هوش مصنوعی، با وجود رشد سریع، با مانع بزرگی روبرو خواهد شد
و این مانع به قدرت پردازشی یا پیشرفتهای الگوریتمی مربوط نمیشود، بلکه مسئلهای بسیار بنیادیتر است: دادههای تاییدنشده و غیرقابل اعتماد. در حالی که دره سیلیکون آخرین دستاوردهای هوش مصنوعی را که میتواند رزرو رستوران انجام دهد یا ایمیلهایتان را بنویسد جشن میگیرد، رهبران کسبوکارها به طور پنهانی در حال متوقف کردن طرحهای چند میلیون دلاری هوش مصنوعی خود هستند. چرا؟ آنها flaw مهلک (نقص کشنده) را کشف کردهاند: هوش مصنوعی که بر اساس دادههای ضعیف ساخته شده، چیزی جز خروجیهای mediocre (معمولی و بیکیفیت) تولید نمیکند.
بحران پنهان پشت وعدههای شکستهشده هوش مصنوعی
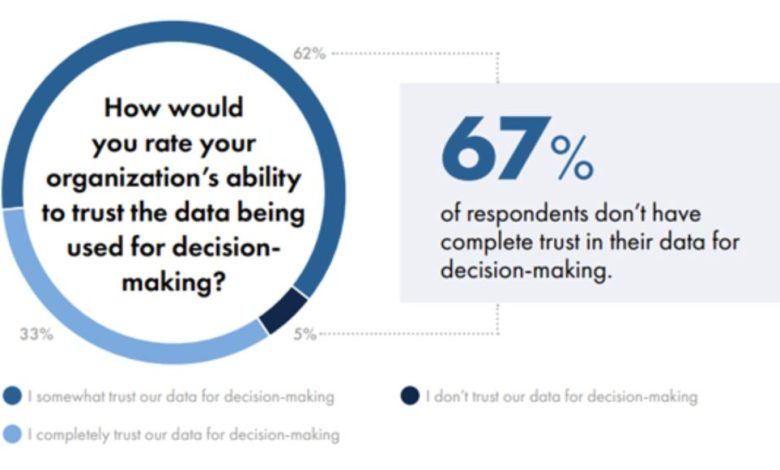
اعداد دروغ نمیگویند. آخرین تحقیقات NTT Data نشان میدهد که ۷۰ تا ۸۵ درصد از استقرارهای generative AI (هوش مصنوعی تولیدی) در برآوردن انتظارات بازگشت سرمایه خود شکست خوردهاند و ۶۷ درصد از سازمانها میگویند که به طور کامل به دادههای مورد استفاده برای تصمیمگیری اعتماد ندارند. این یک مشکل فنی کوچک نیست – این یک flaw اساسی در طراحی (نقص طراحی بنیادی) در نحوه ساخت سیستمهای هوش مصنوعی ماست.
منبع: Precisely
پیشبینی Gartner حتی هشداردهندهتر است: بیش از ۴۰ درصد از پروژههای agentic AI (هوش مصنوعی عاملی) تا سال ۲۰۲۷ لغو خواهند شد. حقیقت ناخوشایند؟ بخش عمدهای از هوش مصنوعی امروزی بر اساس illusion (توهم) ساخته شده است. این سیستمها به هیچ معنای meaningful (معناداری) “یاد” نمیگیرند، آنها فقط حدس میزنند و از کوههایی از دادههای unchecked (بررسینشده)، biased (مغرضانه) یا outright garbage (کاملاً بیمحتوا) استفاده میکنند. آیا به یک ماشین خودران که با علائم جادهای جعلی آموزش دیده اعتماد میکنید؟ یا به یک الگوریتم معاملاتی که با گزارشهای درآمدی manipulated (دستکاریشده) تغذیه میشود؟ با این حال، این واقعیت است: شرکتها آینده خود را بر روی سیستمهای هوش مصنوعی بدون اعتبارسنجی پایه و اساس آن شرط بندی میکنند. ریسک فقط شکست نیست، بلکه catastrophe (فاجعه) است که پشت یک veneer of intelligence (پوستهای از هوشمندی) پنهان شده است.
چرا عاملهای هوش مصنوعی فعلی کورکورانه عمل میکنند
مشکل این نیست که عاملهای هوش مصنوعی ذاتاً flawed (ناقص) هستند، مشکل این است که با دادههای corrupted (آلوده) تغذیه میشوند. سیستمهای متمرکز سنتی این “black box dilemma (معمای جعبه سیاه)” را ایجاد کردهاند: ورودیها و خروجیها visible (قابل مشاهده) هستند، اما مسیر بین آنها یک minefield (میدان مین) از bias (تعصب)، manipulation (دستکاری) و decay (زوال) است.
یک فاجعه واقعی را در نظر بگیرید: یک عامل هوش مصنوعی که بر اساس دادههای بازار آموزش دیده، سرمایهگذاریهایی را توصیه میکند. اما چه میشود اگر دادههای آن شامل گزارشهای manipulated (دستکاریشده)، صورتهای مالی outdated (منسوخ) یا تحقیقات biased (مغرضانه) باشد؟ به چه چیزی منجر میشود؟ هوش مصنوعی فقط شکست نمیخورد؛ با confidence (اطمینان) شکست میخورد و هیچ راهی برای ردیابی یا تصحیح خطا برای enterprises (شرکتها) باقی نمیگذارد.
این hypothetical (فرضی) نیست – تحت سیستم فعلی inevitable (اجتنابناپذیر) است. وقتی یک هوش مصنوعی تصمیمی میگیرد: آیا میتوانید منابع داده آن را audit (بازرسی) کنید؟ آیا میتوانید تأیید کنید که دادههای آموزشی contaminated (آلوده) یا gamed (دستکاری) نشدهاند؟ آیا حتی میتوانید تأیید کنید که سالها out of date (منسوخ) نیستند؟ در بیشتر موارد، پاسخ “خیر” است.
تحقیقات McKinsey damage (آسیب) را تأیید میکند: poor data quality (کیفیت پایین داده) نه تنها performance (عملکرد) را مختل میکند، بلکه به طور فعال trust (اعتماد) به سیستمهای هوش مصنوعی را از بین میبرد. و一旦 اعتماد شکسته شود، هیچ amount of tuning (مقدار تنظیماتی) نمیتواند آن را برطرف کند.
بدترین بخش؟ غولهای فناوری این را میدانند. آنها پشت “proprietary datasets (مجموعه دادههای انحصاری)” پنهان میشوند در حالی که مدلهای آنها خروجیهای biased (مغرضانه)، outdated (منسوخ) یا outright false (کاملاً نادرست) تولید میکنند. این فقط negligent (بیمبالاتی) نیست – یک scam (کلاهبرداری) است. و regulators (مقرراتگذاران)، enterprises (شرکتها) و users (کاربران) finalmente (بالاخره) در حال بیدار شدن هستند.
منبع: McKinsey
بلاکچین: لایه اعتماد گمشده برای دادههای هوش مصنوعی
اینجاست که بلاکچین از being a buzzword (یک عبارت پرطمطراق بودن) دست میکشد و شروع به being a solution (راهحل بودن) میکند. بازارهای داده غیرمتمرکز در حال ظهور اکنون چیزی را ممکن میسازند که قبلاً غیرممکن بود: جریانهای داده real-time (بلادرنگ) و cryptographically verified (تأییدشده رمزنگاری) برای آموزش هوش مصنوعی. پروژههای پیشرو در این تغییر already (هم اکنون) نشان میدهند که چگونه کار میکند: پمپهای داده on-chain (روی زنجیره) که noise (نویز) را فیلتر میکنند، منابع را verify (تأیید) میکنند و تضمین میکنند که only high-quality inputs (فقط ورودیهای باکیفیت) به مدلهای هوش مصنوعی برسد. این فقط در مورد transparency (شفافیت) نیست – این در مورد ساخت هوش مصنوعی است که by design (با طراحی) قابل اعتماد باشد.
هر مجموعه داده با یک lineage (تبار) immutable (تغییرناپذیر) همراه است – منبع، ویرایشها و تاریخچه validation (اعتبارسنجی) – که به enterprises (شرکتها) اجازه میدهد تصمیمات هوش مصنوعی را مانند تراکنشهای مالی audit (بازرسی) کنند. تصور کنید اگر هر قطعه داده مورد استفاده برای آموزش یک عامل هوش مصنوعی، همراه با یک رکورد permanent (دائمی) و tamper-proof (ضد دستکاری) از origin (منشاء