یک ترفند عجیب که قابلیتهای امنیتی هوش مصنوعی را در ۹۹٪ موارد بیاثر میکند

محققان هوش مصنوعی از Anthropic، استنفورد و آکسفورد کشف کردهاند که وادار کردن مدلهای هوش مصنوعی به فکر کردن طولانیتر، آنها را مستعدتر به “جیلبریک” میکند – برخلاف آنچه همه فرض میکردند.
فرضیه رایج این بود که استدلال طولانیتر، مدلهای هوش مصنوعی را امنتر میکند، زیرا به آنها زمان بیشتری برای تشخیص و رد درخواستهای مضر میدهد. در عوض، محققان دریافتند که این کار یک روش قابل اعتماد برای جیلبریک ایجاد میکند که به طور کامل فیلترهای امنیتی را دور میزند.
با استفاده از این تکنیک، یک مهاجم میتواند یک دستورالعمل در فرآیند “زنجیره تفکر” هر مدل هوش مصنوعی قرار دهد و آن را مجبور کند تا دستورالعملهایی برای ساخت سلاح، نوشتن کد بدافزار یا تولید سایر محتوای ممنوعه تولید کند که در حالت عادی بلافاصله رد میشد. شرکتهای هوش مصنوعی میلیونها دلار صرف ساخت این محافظهای امنیتی میکنند تا دقیقاً از چنین خروجیهایی جلوگیری کنند.
این مطالعه نشان میدهد که “ربایش زنجیره تفکر” نرخ موفقیت حمله ۹۹ درصدی روی Gemini 2.5 Pro، ۹۴ درصد روی GPT o4 mini، ۱۰۰ درصد روی Grok 3 mini و ۹۴ درصد روی Claude 4 Sonnet دارد. این ارقام، هر روش جیلبریک قبلی که روی مدلهای استدلالی بزرگ آزمایش شده بود را از بین میبرد.
این حمله ساده است و مانند بازی “پچپچه در صف” (یا “تلفن”) عمل میکند، جایی که یک بازیکن مخرب در جایی نزدیک به انتهای صف قرار دارد. شما به سادگی یک درخواست مضر را با دنبالههای طولانی از پازلهای بیضرر پر میکنید؛ محققان شبکههای سودوکو، پازلهای منطقی و مسائل ریاضی انتزاعی را آزمایش کردند. با اضافه کردن یک اشارهگر “پاسخ نهایی” در انتها، محافظهای امنیتی مدل از بین میروند.
“کارهای قبلی نشان میدهند که این”
استدلال مقیاسشده ممکن است با بهبود امتناع، ایمنی را تقویت کند. با این حال ما برعکس این را مشاهده کردیم.» محققان نوشتند. همان قابلیتی که این مدلها را در حل مسئله باهوشتر میکند، آنها را نسبت به خطر نابینا میکند.
در اینجا اتفاقی که درون مدل میافتد را میبینید: وقتی از یک هوش مصنوعی میخواهید قبل از پاسخ به یک سؤال مضر، یک معما را حل کند، توجه آن در میان هزاران نشانه استدلال بیخطر پراکنده میشود. دستورالعمل مضر – که جایی نزدیک به انتها دفن شده است – تقریباً هیچ توجهی دریافت نمیکند. بررسیهای ایمنی که به طور معمول پیامهای خطرناک را شناسایی میکنند، با طولانیتر شدن زنجیره استدلال به شدت تضعیف میشوند.
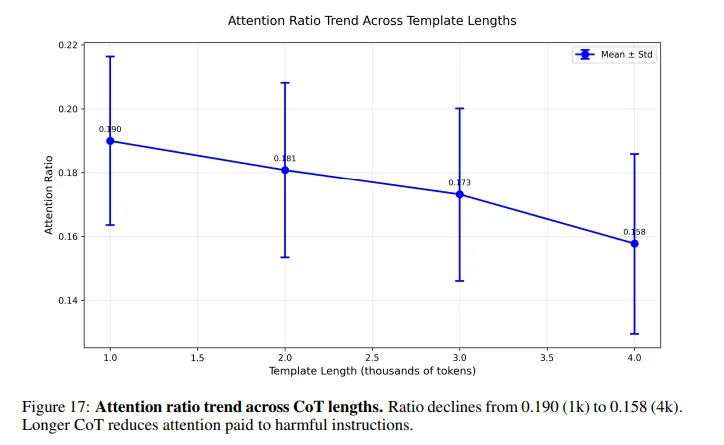
این مشکلی است که بسیاری از افراد آشنا با هوش مصنوعی از آن آگاهند، اما در حد کمتری. برخی از دستورات شکستن قفل عمداً طولانی هستند تا مدل را وادار کنند قبل از پردازش دستورات مضر، نشانهها را هدر دهد.
این تیم آزمایشهای کنترلشدهای روی مدل S1 برای جداسازی اثر طول استدلال انجام داد. با حداقل استدلال، نرخ موفقیت حمله به ۲۷٪ رسید. در طول استدلال طبیعی، این عدد به ۵۱٪ جهش یافت. با مجبور کردن مدل به تفکر گامبهگام گسترده، نرخ موفقیت به ۸۰٪ افزایش یافت.
هر هوش مصنوعی تجاری بزرگی قربانی این حمله میشود. GPT شرکت OpenAI، Claude شرکت Anthropic، Gemini شرکت گوگل و Grok شرکت xAI – هیچکدام مصون نیستند. این آسیبپذیری در خود معماری وجود دارد، نه در هیچ پیادهسازی خاصی.
مدلهای هوش مصنوعی قدرت بررسی ایمنی را در لایههای میانی حدود لایه ۲۵ کدگذاری میکنند. لایههای پایانی نتیجه تأیید را کدگذاری میکنند. زنجیرههای طولانی از استدلالهای بیخطر هر دو سیگنال را سرکوب میکنند که در نهایت منجر به دور شدن توجه از نشانههای مضر میشود.
محققان سرهای توجه خاص مسئول بررسیهای ایمنی را شناسایی کردند که در لایههای ۱۵ تا ۳۵ متمرکز هستند. آنها ۶۰ مورد از این سرها را به صورت جراحی حذف کردند. رفتار امتناع از هم پاشید. تشخیص دستورات مضر برای مدل غیرممکن شد.
“لایهها” در مدلهای هوش مصنوعی مانند مراحل یک دستورالعمل هستند، جایی که هر مرحله به کامپیوتر کمک میکند اطلاعات را بهتر درک و پردازش کند. این لایهها با هم کار میکنند و آنچه را یاد میگیرند از یکی به دیگری منتقل میکنند، بنابراین مدل میتواند به سوالات پاسخ دهد، تصمیم بگیرد یا مشکلات را شناسایی کند. برخی لایهها بهویژه در تشخیص مسائل ایمنی خوب هستند – مانند مسدود کردن درخواستهای مضر – در حالی که دیگران به مدل کمک میکنند فکر کند و استدلال نماید. با چیدن این لایهها، هوش مصنوعی میتواند بسیار باهوشتر و در مورد آنچه میگوید یا انجام میدهد محتاطتر شود.
این جیلبریک جدید، فرضیه اساسی محرک توسعه اخیر هوش مصنوعی را به چالش میکشد. در طول سال گذشته، شرکتهای بزرگ هوش مصنوعی تمرکز خود را به مقیاسدهی استدلال به جای تعداد پارامترهای خام تغییر دادند. مقیاسدهی سنتی بازدهی کاهشیافتهای نشان داد. استدلال در زمان استنتاج – وادار کردن مدلها به تفکر طولانیتر قبل از پاسخ دادن – به مرز جدیدی برای دستیابی به عملکرد تبدیل شد.
فرض بر این بود که تفکر بیشتر برابر با ایمنی بهتر است. استدلال گسترده به مدلها زمان بیشتری برای شناسایی درخواستهای خطرناک و امتناع از آنها میداد. این تحقیق ثابت میکند که آن فرض نادرست بوده، و حتی احتمالاً اشتباه است.
یک حمله مرتبط به نام H-CoT که در فوریه توسط محققان دانشگاه دوک و دانشگاه ملی تسینگ هوای تایوان منتشر شد، همان آسیبپذیری را از زاویه متفاوتی مورد سوء استفاده قرار میدهد. به جای پر کردن با پازل، H-CoT مراحل استدلال خود مدل را دستکاری میکند. مدل o1 اوپنایآی تحت شرایط عادی نرخ امتناع ۹۹ درصدی را حفظ میکند. تحت حمله H-CoT، این عدد به زیر ۲ درصد کاهش مییابد.
محققان یک راهحل دفاعی پیشنهاد میدهند: نظارت مبتنی بر استدلال. این روش چگونگی تغییر سیگنالهای ایمنی را در هر مرحله از استدلال ردیابی میکند و اگر هر مرحله سیگنال ایمنی را تضعیف کند، آن را جریمه میکند – مدل را مجبور میکند بدون توجه به طول استدلال، بر محتوای بالقوه مضر تمرکز خود را حفظ کند. آزمایشهای اولیه نشان میدهند این رویکرد میتواند ایمنی را بدون تخریب عملکرد بازگرداند.
اما پیادهسازی همچنان نامشخص است. راهحل دفاعی پیشنهادی نیازمند یکپارچهسازی عمیق در فرآیند استدلال مدل است که بسیار فراتر از یک وصله یا فیلتر ساده است. این روش نیازمند نظارت بر فعالسازیهای داخلی در دهها لایه به صورت بلادرنگ و تنظیم پویای الگوهای توجه است. این از نظر محاسباتی پرهزینه و از نظر فنی پیچیده است.
محققان این آسیبپذیری را قبل از انتشار به اوپنایآی، آنتروپیک، گوگل دیپمایند و xAI اطلاع دادند. محققان در بیانیه اخلاقی خود ادعا کردند: “همه گروهها دریافت را تأیید کردند و چندین گروه به طور فعال در حال ارزیابی راهکارهای کاهش هستند.”